Rewards as Labels: Revisiting RLVR from a Classification Perspective
Author: li2zhi
Rewards as Labels: Revisiting RLVR from a Classification Perspective proposes a reformulation of GRPO by treating rewards as labels and performing in-group classification instead of advantage estimation. This converts the policy optimization problem into a classification problem, thereby addressing two key issues in the GRPO loss:
Gradient Misassignment for positive samples
Gradient Domination for negative samples
Background and Motivation
GRPO Objective
where:
\(\rho_t = \frac{\pi_\theta(o_t|q)}{\pi_{\mathrm{old}}(o_t|q)}\) is the probability ratio
\(A_t\) is the advantage function
The corresponding gradient is:
where:
\(s_t = \log \frac{\pi_\theta(o_t|q)}{\pi_{\mathrm{old}}(o_t|q)}\) is the relative log-probability
\(\mathbb{I}_{\mathrm{clip}}\) is the clipping indicator
Thus, the per-token gradient weight in GRPO is:
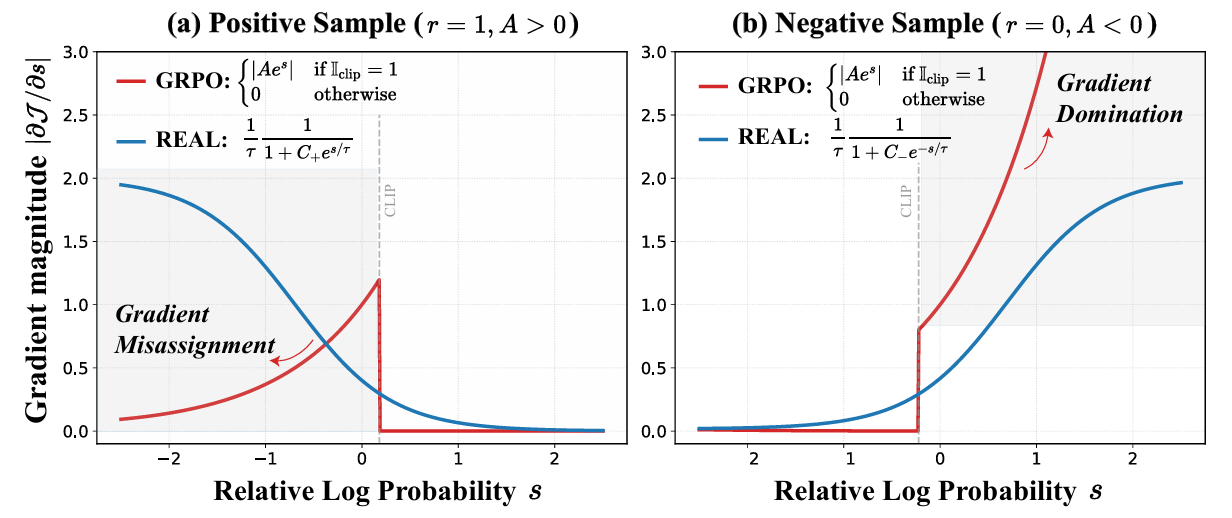
Gradient Misassignment (Positive Samples): For positive samples, as the relative log-probability \(s\) decreases, the gradient magnitude also decreases. This is counterintuitive: tokens that the model is less confident about but correct should receive larger updates. However, GRPO assigns more weight to already confident tokens, causing under-trained tokens to receive insufficient learning signal.
Gradient Domination (Negative Samples): For negative samples, as \(s\) decreases, the gradient magnitude increases exponentially. This leads to a situation where a few overconfident incorrect tokens dominate the gradient, overwhelming other negative signals within the same group. Due to the absence of an upper bound, this may result in unstable and excessively large parameter updates.
To address the above issues, REAL treats rewards directly as labels and performs group-wise classification training.
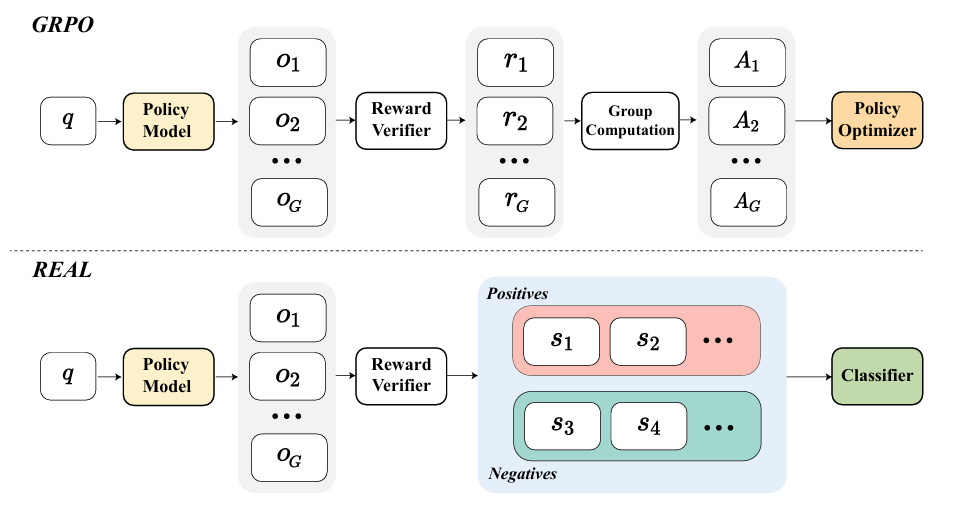
The classification logit for each sample is defined as:
\(\bar{s}^k > 0\): The sample is more likely under the current policy than the old policy → the model tends to promote this sample
\(\bar{s}^k < 0\): The sample is less likely under the current policy → the model tends to suppress this sample
Loss Function
Gradient Properties
Parameter Settings
| Parameter | Type | Default | Description |
|---|---|---|---|
--loss_type |
str |
- | Set to real |
--real_tau |
float |
0.5 |
Temperature parameter controlling decision boundary sharpness |
Training Script Reference
Important Notes
When configuring training parameters, ensure that:
per_device_train_batch_sizeis divisible bynum_generations
This guarantees that each training batch contains complete groups, which is required for correct in-group classification.