Soft Adaptive Policy Optimization (SAPO)
Soft Adaptive Policy Optimization (SAPO) addresses the issues caused by hard clipping in GRPO by proposing a temperature-controlled soft gate mechanism that smoothly attenuates off-policy updates while preserving useful learning signals.
Background and Motivation
When training LLMs with reinforcement learning, GRPO handles off-policy training by computing token-level importance sampling ratios:
However, token-level importance sampling ratios often exhibit high variance, which can be exacerbated in the following cases:
Long text generation
MoE model routing heterogeneity: The old-policy model during sampling and the training model may use different expert routing, significantly amplifying logps differences
To address this, GRPO uses hard clipping to limit the magnitude of policy updates:
The Dilemma of Hard Clipping: Hard clipping struggles to balance stability and learning efficiency—too strict clipping limits the number of effective samples, while too loose clipping introduces noisy gradients from off-policy samples, leading to training instability.
SAPO Method
SAPO uses a temperature-controlled sigmoid soft gate function to replace hard clipping, achieving smooth gradient attenuation.
Soft Gate Function
The core of SAPO is using the sigmoid function to apply soft gating on the importance sampling ratio:
For positive advantages (\(A > 0\)), use positive gating:
For negative advantages (\(A < 0\)), use negative gating:
where:
\(\sigma(\cdot)\) is the sigmoid function
\(\tau_{\mathrm{pos}}\) and \(\tau_{\mathrm{neg}}\) are temperature parameters that control the gate function slope
\(r_t\) is the importance sampling ratio
SAPO Loss Function
where \(g_t = g^{+}_t\) when \(A > 0\), \(g_t = g^{-}_t\) when \(A < 0\).
Temperature Parameters
The temperature parameter \(\tau\) controls the decay rate of the soft gate function—larger values result in faster decay.
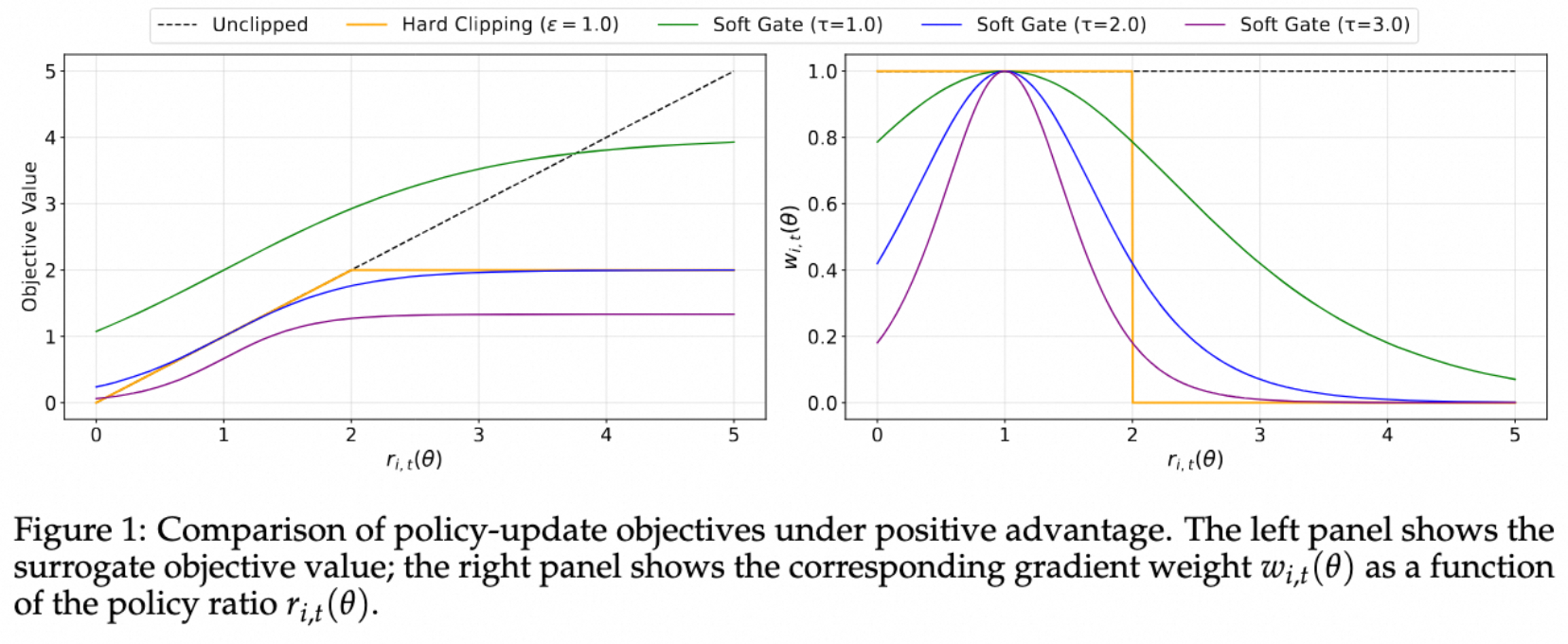
The paper points out that positive advantages increase the logit of sampled tokens while decreasing the logits of all unsampled tokens; negative advantages do the opposite, increasing the logits of many unsampled tokens, which may spread to a large number of irrelevant tokens and introduce instability. Therefore, the paper recommends setting \(\tau_\text{neg} > \tau_\text{pos}\) to make the gradient decay faster for tokens with negative rewards, improving training stability and performance.
The paper recommends default values of \(\tau_{\mathrm{pos}} = 1.0\) and \(\tau_{\mathrm{neg}} = 1.05\).
Parameter Settings
| Parameter | Type | Default | Description |
|---|---|---|---|
--loss_type |
str |
- | Set to sapo |
--tau_pos |
float |
1.0 |
Temperature parameter for positive advantages, controls gate slope |
--tau_neg |
float |
1.05 |
Temperature parameter for negative advantages, controls gate slope |
swift rlhf \
--rlhf_type grpo \
--loss_type sapo \
--tau_pos 1.0 \
--tau_neg 1.05 \
# ... other parameters
Example training scripts:
The soft gate mechanism of SAPO only takes effect during off-policy training. The importance sampling granularity in SAPO is at the token level (i.e., importance_sampling_level defaults to token), which conflicts with GSPO.