DeepSeek-V4 训练支持
目前Megatron-SWIFT支持了DeepSeek-V4的微调与RL支持,包括MTP、FP8等特性。(FP4 blockwise训练暂时不支持,会在加载权重时自动转成FP8/BF16)
你需要使用Megatron-Core dev分支以及mcore-bridge、ms-swift main分支。
pip install git+https://github.com/NVIDIA/Megatron-LM.git@dev
pip install git+https://github.com/modelscope/mcore-bridge.git
pip install git+https://github.com/modelscope/ms-swift.git
精度对齐
目前Megatron-Core对DeepSeek-V4的支持算子实现有误,存在精度误差(后续可能更新),具体查看这个issue。你需要修改部分代码:
修改这行,修改为
mixed = torch.bmm(h_res_batched.transpose(-1, -2), residual_batched).view(s, b, n, C)修改这行,修改为
h_res_batched = h_res.transpose(-1, -2).contiguous().view(s * b, n, n)此外为了支持精度对齐测试(FP32),你需注释掉这几行。
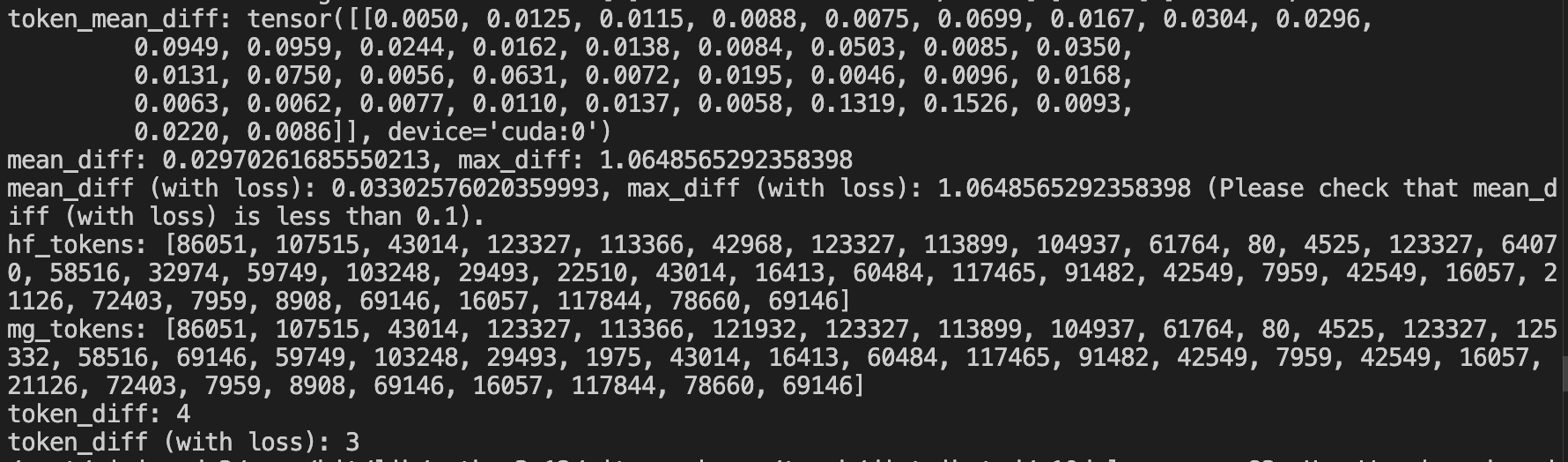
修改完代码后,测试以下代码,确认无实现错误(测试transformers/megatron forward对齐情况):
创建mini版本的模型,我们将创建4层:
import os
import torch
from modelscope.hub.file_download import model_file_download
from safetensors.torch import safe_open
from swift import safe_snapshot_download
from mcore_bridge.utils import Fp8Dequantizer, SafetensorLazyLoader, StreamingSafetensorSaver
model_id = 'deepseek-ai/DeepSeek-V4-Flash-Base'
# Some models have the first few layers as dense and the rest as MoE; set this value accordingly
model_dir = safe_snapshot_download(model_id, download_model=False)
loader = SafetensorLazyLoader(model_dir)
state_dict = loader.get_state_dict()
saver = StreamingSafetensorSaver(save_dir=model_dir)
fp8_dequantizer = Fp8Dequantizer() # Used to convert fp8 weights to bf16
def _open_file(self, filename: str):
if filename not in self._file_handles:
file_path = os.path.join(self.hf_model_dir, filename)
tmp_dir = os.path.join(self.hf_model_dir, 'tmp')
if not os.path.exists(file_path):
file_path = os.path.join(tmp_dir, filename)
if not os.path.exists(file_path):
file_path = model_file_download(
model_id=model_id,
file_path=filename,
local_dir=tmp_dir,
)
self._file_handles[filename] = safe_open(file_path, framework='pt')
return self._file_handles[filename]
SafetensorLazyLoader._open_file = _open_file # monkey patch (lazy downloading)
new_state_dict = {}
for k, v in state_dict.items():
if k.startswith('layers.'):
idx = int(k[len('layers.'):].split('.', 1)[0])
if idx >= 4:
continue
if k.endswith('.scale'):
continue
elif k.endswith('.weight'):
weight_scale_inv = k.replace('.weight', '.scale')
if weight_scale_inv in state_dict:
v = fp8_dequantizer.convert(v.load(), state_dict[weight_scale_inv].load()).to(torch.bfloat16)
new_state_dict[k] = v if isinstance(v, torch.Tensor) else v.load()
for k, v in new_state_dict.items():
saver.add_tensor(k, v)
saver.finalize()
然后修改config.json:
num_hidden_layers修改为
4。compress_ratios修改为
[0, 0, 4, 128, 0]。删除
quantization_config。
然后创建test.py,使用以下命令运行:CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 test.py。更多参考自定义Megatron模型文档。
import os
os.environ['SWIFT_TEST_CONVERT_PRECISION'] = '1'
from swift.megatron import MegatronExportArguments, megatron_export_main
from swift import safe_snapshot_download
model_id = 'deepseek-ai/DeepSeek-V4-Flash-Base'
model_dir = safe_snapshot_download(model_id, download_model=False)
if __name__ == '__main__':
megatron_export_main(
MegatronExportArguments(
model=model_dir,
to_mcore=True,
attention_backend='flash',
tensor_model_parallel_size=1,
pipeline_model_parallel_layout='Et*3|t*1mL',
pipeline_model_parallel_size=2,
expert_model_parallel_size=2,
mtp_num_layers=1,
test_convert_precision=True,
))
当出现以下结果时,则表示对齐没有问题,可以进行训练了。
LoRA训练
BF16精度LoRA训练脚本如下,最后会保存LoRA增量权重和Merge-LoRA后的BF16完整权重。
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
NPROC_PER_NODE=8 \
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
megatron sft \
--model deepseek-ai/DeepSeek-V4-Flash \
--save_safetensors true \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#1000' \
'AI-ModelScope/alpaca-gpt4-data-en#1000' \
'swift/self-cognition#1000' \
--model_author swift \
--model_name swift-robot \
--merge_lora true \
--load_from_cache_file true \
--add_non_thinking_prefix true \
--loss_scale ignore_empty_think \
--split_dataset_ratio 0.01 \
--tuner_type lora \
--lora_rank 16 \
--lora_alpha 32 \
--tensor_model_parallel_size 1 \
--expert_model_parallel_size 8 \
--micro_batch_size 4 \
--global_batch_size 32 \
--padding_free false \
--group_by_length true \
--recompute_granularity full \
--recompute_method uniform \
--recompute_num_layers 1 \
--moe_permute_fusion true \
--moe_grouped_gemm true \
--moe_shared_expert_overlap true \
--moe_aux_loss_coeff 1e-3 \
--num_train_epochs 1 \
--finetune true \
--cross_entropy_loss_fusion true \
--lr 1e-4 \
--lr_warmup_fraction 0.05 \
--min_lr 1e-5 \
--output_dir megatron_output/DeepSeek-V4-Flash \
--eval_steps 200 \
--save_steps 200 \
--max_length 4096 \
--dataloader_num_workers 8 \
--dataset_num_proc 8 \
--no_save_optim true \
--no_save_rng true \
--sequence_parallel true \
--mtp_num_layers 1 \
--attention_backend flash
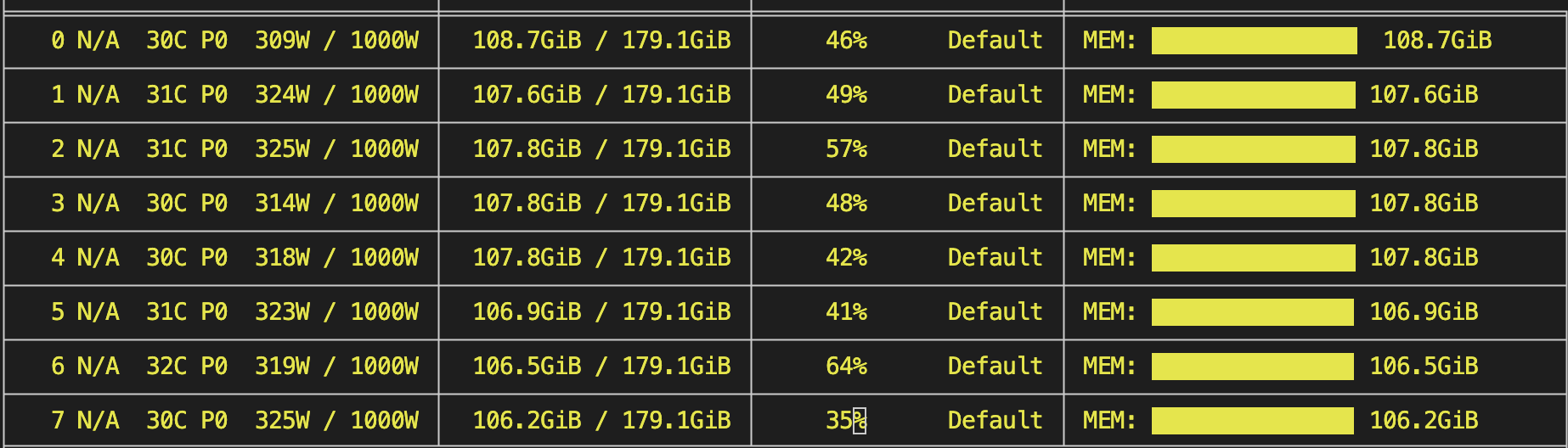
显存占用:
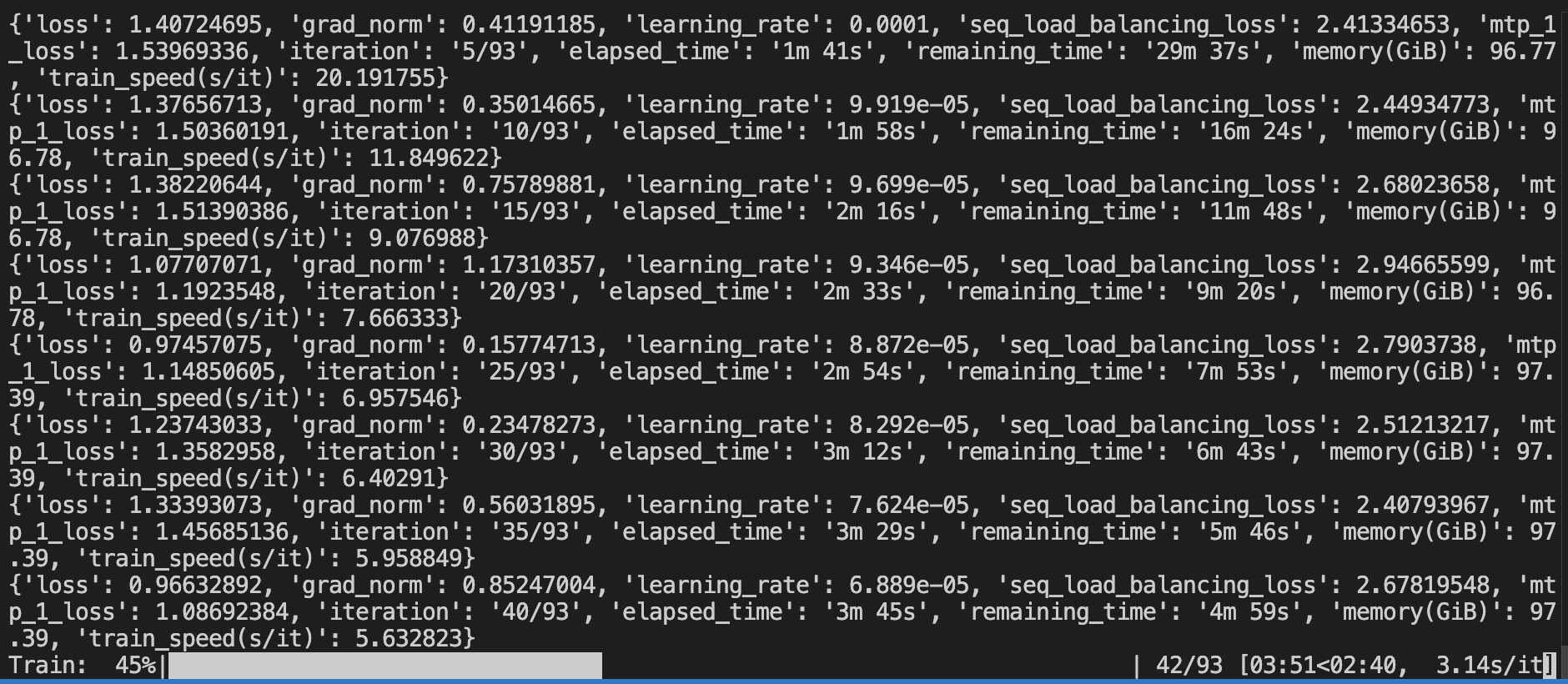
训练日志与损失:
提示:
如果你要设置pp并行,你需要额外设置
pipeline_model_parallel_layout。例如:
--pipeline_model_parallel_size 2 \
--pipeline_model_parallel_layout 'Et*22|t*21mL' \
全参数训练也是支持的,你需要降低learning_rate,并提高并行数。参考64卡训练例子:
--lr 1e-5 \
--min_lr 1e-6 \
--tensor_model_parallel_size 1 \
--expert_model_parallel_size 8 \
--pipeline_model_parallel_size 8 \
--pipeline_model_parallel_layout Et*5|t*5|t*6|t*6|t*6|t*5|t*5|t*5mL \
暂时不支持
padding_free和packing,但可以通过group_by_length加速。暂时不支持TP,待Megatron-Core支持。FP8训练:你可以设置以下参数开启FP8训练,并最终将权重保存成FP8权重。推荐使用全参数训练。如果要使用LoRA + FP8,你需要只保存LoRA权重(设置
--merge_lora false),并使用BF16权重进行Merge-LoRA(FP8 精度有限,LoRA delta 会被舍入为 0)。参考这个例子。
--fp8_recipe blockwise \
--fp8_format e4m3 \
--fp8_param_gather true \
推理训练后的模型:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
swift infer \
--model megatron_output/DeepSeek-V4-Flash/vx-xxx/checkpoint-xxx-merged \
--infer_backend transformers \
--enable_thinking false \
--max_new_tokens 2048
推理结果:
