TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
作者: li2zhi
原理介绍
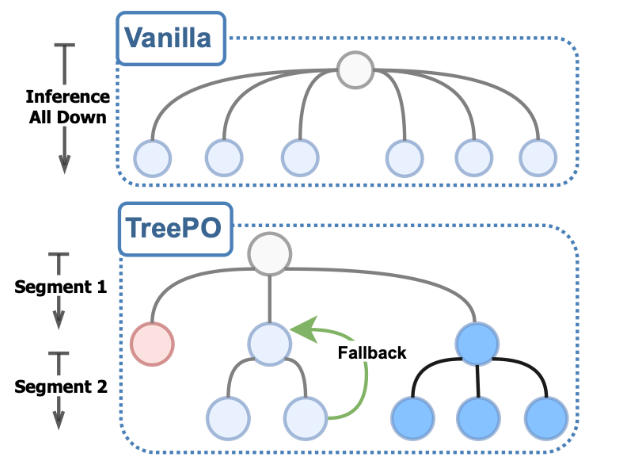
TreePO论文 提出了一种树状结构建模方法。该方法将序列生成组织为分段式的树结构搜索,通过动态分支、回退与提前终止机制,显著提高KV缓存复用率,从而降低计算开销,同时保持甚至增强了探索的多样性。
实现细节
TreePO实现示例参考官方实现 给出了 TreePO 训练插件的样例代码,涵盖了多轮交互、终止判断,与分支回退等相关逻辑。
注意:在实际使用中,你需要根据自己的场景需求,重写step、check_finished等方法的逻辑,以确保其能够在自定义场景下按照预期执行。而关于自定义奖励的设计与使用,你可以参考DeepEyes的实现。
训练参考该脚本
测试数据
model: Qwen/Qwen2.5-0.5B dataset: AI-MO/NuminaMath-TIR subset size: 1,000 samples 1 GPU for training, 1 GPU for inference
| \ | batch_size | num_generation | max_tree_depth | global_step | total inference calls | saving ratio | train_speed(iter/s) | improvement rate |
|---|---|---|---|---|---|---|---|---|
| original implementation | 8 | 8 | 4 | 200 | 5965 | 0.00% | 0.292436 | 0.00% |
| tree(max_divergence=3) | 8 | 8 | 4 | 200 | 3678 | 38.34% | 0.31819 | 8.81% |
| original implementation | 8 | 8 | 5 | 105 | 4312 | 0.00% | 0.261324 | 0.00% |
| tree(max_divergence=2) | 8 | 8 | 5 | 105 | 2513 | 52.69% | 0.336639 | 28.82% |
| tree(max_divergence=3) | 8 | 8 | 5 | 105 | 2990 | 30.66% | 0.308791 | 18.16% |
| original implementation | 8 | 8 | 6 | 105 | 5202 | 0.00% | 0.24832 | 0.00% |
| tree(max_divergence=2) | 8 | 8 | 6 | 105 | 3348 | 35.64% | 0.27755 | 11.77% |
| tree(max_divergence=3) | 8 | 8 | 6 | 105 | 3888 | 25.26% | 0.272339 | 9.67% |